Test method
return boolean
Match Literal Strings
let testStr = "freeCodeCamp";
let testRegex = /Code/;
let testRegex2 = /free|code/;
testRegex.test(testStr); // return true
testRegex2.test(testStr); // return true
Ignore case
use flag : i
let myString = "freeCodeCamp";
let fccRegex = /freecodecamp/i;
let result = fccRegex.test(myString); // return trueExtract Matches
get found matches
"Hello, World!".match(/Hello/);
// Returns ["Hello"]find more than the first match
use flag : g
let testStr = "Repeat, Repeat, Repeat";
let singleRegex = /Repeat/;
let globalRegex = /Repeat/g;
testStr.match(singleRegex); // Returns ["Repeat"]
testStr.match(globalRegex); // Returns ["Repeat", "Repeat", "Repeat"]Match Single Character with Multiple Possibilities
wildcard character: .
let humStr = "I'll hum a song";
let hugStr = "Bear hug";
let huRegex = /hu./;
humStr.match(huRegex); // Returns ["hum"]
hugStr.match(huRegex); // Returns ["hug"]character classes
placing a group of characters inside square ([and ]) brackets.
let bigStr = "big";
let bagStr = "bag";
let bogStr = "bog";
let bgRegex = /b[aiu]g/;
bigStr.match(bgRegex); // Returns ["big"]
bagStr.match(bgRegex); // Returns ["bag"]
bogStr.match(bgRegex); // Returns nullcharacter set
Using the hyphen (-) to match a range of characters
let catStr = "cat";
let batStr = "bat";
let matStr = "mat";
let bgRegex = /[a-e]at/;
catStr.match(bgRegex); // Returns ["cat"]
batStr.match(bgRegex); // Returns ["bat"]
matStr.match(bgRegex); // Returns nullnegated character sets
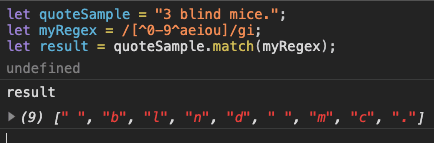
place a caretcharacter (^) after the opening bracket and before the characters you do not want to match.
Match 0 or more times
 use the
use the + character to check if that is the case. Remember, the character or pattern has to be present consecutively.
0 or more times
the asteriskor star: *
let soccerWord = "gooooooooal!";
let gPhrase = "gut feeling";
let oPhrase = "over the moon";
let goRegex = /go*/;
soccerWord.match(goRegex); // Returns ["goooooooo"]
gPhrase.match(goRegex); // Returns ["g"]
oPhrase.match(goRegex); // Returns null1 or more times
use the + character.
Remember, the character or pattern has to be present consecutively.
const regex = /a+/gi;
"abc".match(regex); // return ['a']
"aabc".match(regex); // return ['aa']
"abab".match(regex); // return ['a','a']Quantity specifiers
with curly brackets ({and }). You put two numbers between the curly brackets - for the lower and upper number of patterns.
let A4 = "aaaah";
let A2 = "aah";
let multipleA = /a{3,5}h/;
multipleA.test(A4); // Returns true
multipleA.test(A2); // Returns false
let atLeast3A = /a{3,}h/;
let exact3A = /a{3}h/;Lazy matching
const greedyRegex = /t[a-z]*i/
const lazyRegex = /t[a-z]*?i/
const str = 'titanic'
str.match(greedyRegex); // return ['titani']
str.match(lazyRegex); // return ['ti']Regular expressions are by default greedy, so the match would return ["titani"]. It finds the largest sub-string possible to fit the pattern.
The alternative is called a lazymatch, which finds the smallest possible part of the string that satisfies the regex pattern.
Match Beginning/Ending
^ Beginning
(^) inside a character set,
create a negated character setin the form [^thingsThatWillNotBeMatched].
===
(^) outside of a character set,
used to search for patterns at the beginning of strings.
let firstString = "Ricky is first and can be found.";
let firstRegex = /^Ricky/;
firstRegex.test(firstString); // Returns true
let notFirst = "You can't find Ricky now.";
firstRegex.test(notFirst); // Returns false$ Ending
let theEnding = "This is a never ending story";
let storyRegex = /story$/;
storyRegex.test(theEnding); // Returns true
let noEnding = "Sometimes a story will have to end";
storyRegex.test(noEnding); // Returns falseshorthand character classes
\wis equal to[A-Za-z0-9_], words\Wis equal to[^A-Za-z0-9_]\dis equal to[0-9], digital cahracters\Dis equal to[^0-9]\sis equal to[ \r\t\f\n\v], matches whitespace, but also carriage return, tab, form feed, and new line characters.\Sis equal to[^ \r\t\f\n\v], non-whitespace characters